En los últimos tiempos ha habido grandes descubrimientos que han revolucionado el campo de procesamiento del lenguaje natural (PLN) y uno de ellos son los word embeddings (conocidos en español como: incrustación o incrustaciones de palabras). Esta técnica consiste en representar palabras a manera de vectores de números, lo que ha permitido mejorar significativamente las tareas de descubrimiento de conocimiento y de recomendación de contenido.
La teoría y algunos de los usos tempranos de esta técnica se remontan a los años 90; sin embargo, no se popularizó sino hasta el 2013 cuando un grupo de cientistas de la computación desarrolló word2vec, que es un método simple para la creación de word embeddings. En este artículo explicamos brevemente de qué se trata esta técnica y cómo la utilizamos dentro del BID para proyectos de gestión de conocimiento.
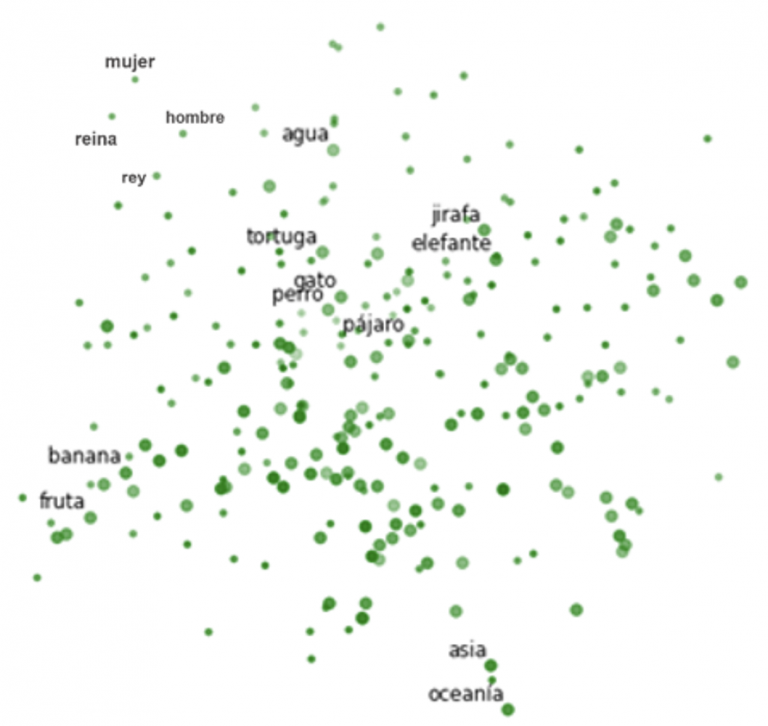
Imagina una nube en el espacio compuesta por palabras. En esta nube, el lugar donde se encuentran las palabras es importante ya que determina su significado. Como vemos en la imagen, la cual es una visualización de esta nube, tenemos en una sección palabras asociadas a animales, y en otra encontramos palabras asociadas a alimentos. Dentro del grupo de palabras de animales, también vemos que las palabras asociadas a mascotas se encuentran más cercanas entre ellas, ej. gato y perro, en comparación con las palabras que hacen referencia a animales salvajes, ej. jirafa y elefante. No solo eso, en la imagen podemos observar otro tipo de patrones, por ejemplo, vemos que la distancia entre las palabras hombre y rey, es la misma que la distancia entre las palabras mujer y reina.
Esta estructura es lo que descubrieron los cientistas de la computación que mencionamos anteriormente. Al entrenar a un algoritmo, usando un sinnúmero de documentos que contenían todo tipo de vocabulario, consiguieron representar palabras como vectores para determinar su lugar en el espacio y hacer aritmética con ellas.
¿Cómo se usan los word embeddings?
Actualmente, la técnica es usada en diversas aplicaciones como sistemas de búsqueda, sistemas de recomendación, traducción de texto y muchas veces es el paso previo en el procesamiento de los datos de texto que posteriormente permite hacer tareas de clasificación de documentos y análisis de sentimiento, etc.
En la división de conocimiento y aprendizaje del BID, hemos usado los word embeddings para crear herramientas de búsqueda inteligente. Haciendo uso de más de 200,000 documentos operacionales y corporativos del BID, entrenamos un algoritmo para crear estos word embeddings en los 4 idiomas oficiales del banco, y como resultado obtuvimos un modelo del lenguaje que es representativo del desarrollo económico en América Latina y el Caribe.
Nuestra experiencia más reciente con esta herramienta fue durante el desarrollo de la plataforma Findit, cuya finalidad es conectar usuarios con fuentes distintas de conocimiento, incluyendo documentos y personas, y es también un motor de búsqueda de lecciones aprendidas recabadas a lo largo del ciclo de proyecto de préstamos del BID.
Dos tipos de búsqueda usando word embeddings
Por asociación de palabras
Encontrar palabras similares nos permite hacer búsquedas más comprensivas logrando resultados más completos. Por ejemplo, si un usuario busca Economía Digital, nuestro motor de búsqueda también busca las palabras asociadas y recomienda contenido.
Haciendo aritmética con las palabras para descubrir asociaciones
Otra forma de encontrar asociaciones entre palabras para enriquecer los resultados de búsqueda es haciendo aritmética con las palabras. Por ejemplo, usando nuestro modelo vemos que la suma de las palabras transporte y verde devuelve los siguientes términos: transporte urbano, bicicleta, transporte público.
Ahora que ya hemos explicado lo que son los word embeddings y algunas de sus aplicaciones, quizá te preguntes sobre los recursos que puedes utilizar para el entrenamiento de algoritmos. Efectivamente, existen diversas librerías para este fin y una de las más populares es: gensim. Esta librería está escrita en Python y si tienes un número grande de documentos que quieras explorar e incorporar este modelo en tu área de trabajo, gensim incluye tutoriales que explican cómo entrenar el algoritmo paso a paso. La herramienta también cuenta con modelos pre entrenados que los puedes descargar y empezar a explorar en solo un par de líneas de código.
Fuente: Abierto al Publico
No hay comentarios.:
Publicar un comentario